Chat and command your own embedded-AI companion bot using local LLMs.
Imagine a fully autonomous robotic companion, like Baymax from Disney’s Big Hero 6 — a friendly, huggable mechanical being that can walk, hold lifelike interactive conversations, and, when necessary, fight crime. Thanks to the advent of large language models (LLMs), we’re closer to this science fiction dream becoming a reality — at least for lifelike conversations.
In this guide I’ll introduce Digit, a companion bot that I helped create with Jorvon Moss (@Odd_jayy). It uses a small LLM running locally on an embedded computer to hold conversations without the need for an internet connection.
I’ll also walk you through the process of running a similar, lightweight LLM on a Raspberry Pi so you can begin making your own intelligent companion bot.
What Is a Large Language Model (LLM)?
A large language model is a specific type of AI that can understand and generate natural, human-like text. The most popular example of an LLM right now is OpenAI’s ChatGPT, which is used to answer questions for the curious, automatically generate social media content, create code snippets and, to the chagrin of many English teachers, write term papers. LLMs are, in essence, the next evolution of chatbots.
LLMs are based on the neural network architecture known as a transformer. Like all neural networks, transformers have a series of tunable weights for each node to help perform the mathematical calculations required to achieve their desired task. A weight in this case is just a number — think of it like a dial in a robot’s brain that can be turned to increase or decrease the importance of some piece of information. In addition to weights, transformers have other types of tunable dials, known as parameters, that help convert words and phrases into numbers as well as determine how much focus should be given to a particular piece of information.
Instead of humans manually tuning these dials, imagine if the robot could tune them itself. That is the magic of machine learning: training algorithms adjust the values of the parameters (dials) automatically based on some goal set by humans. These training algorithms are just steps that a computer can easily follow to calculate the parameters. Humans set a goal and provide training data with correct answers to the training algorithms. The AI looks at the training data and guesses an answer. The training algorithm determines how far off the AI’s result is from the correct answer and updates the parameters in the AI to make it better next time. Rinse and repeat until the AI performs at some acceptable level.
To give you an idea of complexity, a machine learning model that can read only the handwritten digits 0 through 9 with about 99% accuracy requires around 500,000 parameters. Comprehending and generating text are vastly more complicated. LLMs are trained on large quantities of human-supplied text, such as books, articles, and websites. The main goal of LLMs is to predict the next word in a sequence given a long string of previous words. As a result, the AI must understand the context and meaning of the text. To achieve this, LLMs are made up of massive amounts of parameters. ChatGPT-4, released in June 2023, is built from eight separate models, each containing around 220 billion parameters — about 1.7 trillion total.
Why a Local LLM?
The billions of calculations needed for ChatGPT to hold a simple conversation require lots of large, internet-connected servers. If you tried to run ChatGPT on your laptop, assuming you even had enough memory to store the model, it would take hours or days to get a response! In most cases, relying on servers to do the heavy lifting is perfectly acceptable. After all, we use copious cloud services as consumers, such as video streaming, social media, file sharing, and email.
However, running an LLM locally on a personal computer might be enticing for a few reasons:
- Maybe you require access to your AI in areas with limited internet access, such as remote islands, tropical rainforests, underwater, underground caves, and most technology conferences!
- By running the LLM locally, you can also reduce network latency — the time it takes for packets to travel to and from servers. That being said, the extra computing power from the servers often makes up for the latency time for complex tasks like LLMs.
- Additionally, you can assume greater privacy and security for your data, which includes the prompts, responses, and model itself, as it does not need to leave the privacy of your computer or local network. If you’re an AI researcher developing the next great LLM, you can better protect your intellectual property by not exposing it to the outside.
- Personal computers and home network servers are often smaller than their corporate counterparts used to run commercial LLMs. While this might limit the size and complexity of your LLM, it often means reduced costs for such operations.
- Finally, most commercial LLMs contain a variety of guardrails and limits to prevent misuse. If you need an LLM to operate outside of commercial limits — say, to inject your own biases to help with a particular task, such as creative writing — then a local LLM might be your only option.
Thanks to these benefits, local LLMs can be found in a variety of instances, including healthcare and financial systems to protect user data, industrial systems in remote locations, and some autonomous vehicles to interact with the driver without the need for an internet connection. While these commercial applications are compelling, we should focus on the real reason for running a local LLM: building an adorable companion bot that we can talk to.
Introducing Digit
Jorvon Moss’s robotic designs have improved and evolved since his debut with Dexter (Make: Volume 73), but his vision remains constant: create a fully functioning companion robot that can walk and talk. In fact, he often cites Baymax as his goal for functionality. In recent years, Moss has drawn upon insects and arachnids for design inspiration. “I personally love bugs,” he says. “I think they have the coolest design in nature.”
Digit’s body consists of a white segmented exoskeleton, similar to a pill bug’s, that protects the sensitive electronics. The head holds an LED array that can express emotions through a single, animated “eye” along with a set of light-up antennae and controllable mandibles. It sits on top of a long neck that can be swept to either side thanks to a servomotor. Digit’s legs cannot move on their own but can be positioned manually.
Like other companion bots, Digit can be perched on Moss’s shoulder to catch a ride. A series of magnets on Digit’s body and feet help keep it in place.

But Digit is unique from Moss’s other companion bots thanks to its advanced brain — an LLM running locally on an Nvidia Jetson Orin Nano embedded computer. Digit is capable of understanding human speech (English for now), generating a text response, and speaking that response aloud — without the need for an internet connection. To help maintain Digit’s relatively small size and weight, the embedded Jetson Orin Nano was mounted on a wooden slab along with an LCD for startup and debugging. Moss totes both the Orin Nano and the appropriate battery in a backpack. You could design your own companion bot differently to house the Orin Nano inside.

How Digit’s Brain Works
I helped Moss design and program the software system to act as Digit’s AI brain. This system is comprised of three main components: a service running the LLM, a service running the text-to-speech system, and a client program that interacts with these two services.

The client, called hopper-chat, controls everything. It continuously listens for human speech from a microphone and converts everything it hears using the Alpha Cephei Vosk speech-to-text (STT) library. Any phrases it hears are compared to a list of wake words/phrases, similar to how you might say “Alexa” or “Hey, Siri” to get your smart speaker to start listening. For Digit, the wake phrase is, unsurprisingly, “Hey, Digit.” Upon hearing that phrase, any new utterances are converted to text using the same Vosk system.
The newly generated text is then sent to the LLM service. This service is a Docker container running Ollama, an open-source tool for running LLMs. In this case, the LLM is Meta’s Llama3:8b model with 8 billion parameters. While not as complex as OpenAI’s ChatGPT-4, it still has impressive conversational skills. The service sends the response back to the hopper-chat client, which immediately forwards it to the text-to-speech (TTS) service.
TTS for hopper-chat is a service running Rhasspy Piper that encapsulates the en_US-lessac-low model, a neural network trained to produce sounds when given text. In this case, the model is specifically trained to produce English words and phrases in an American dialect. The “low” suffix indicates that the model is low quality — smaller size, more robotic sounds, but faster execution. The hopper-chat program plays any sounds it receives from the TTS service through a connected speaker.
On Digit, the microphone is connected to a USB port on the Orin Nano and simply draped over a backpack strap. The speaker is connected via Bluetooth. Moss uses an Arduino to monitor activity in the Bluetooth speaker and move the mandibles during activity to give Digit the appearance of speaking.
Moss added several fun features to give Digit a distinct personality. First, Digit tells a random joke, often a bad pun, every minute if the wake phrase is not heard. Second, Moss experimented with various default prompts to entice the LLM to respond in particular ways. This includes making random robot noises when generating a response and adopting different personalities, from helpful to sarcastic and pessimistic.

Agency: From Text to Action
The next steps for Digit involve giving it a form of self-powered locomotion, such as walking, and having the LLM perform actions based on commands. On their own, LLMs cannot perform actions. They simply generate text responses based on input. However, adjustments and add-ons can be made that allow such systems to take action. For example, ChatGPT already has several third-party plugins that can perform actions, such as fetching local weather information. The LLM recognizes the intent of the query, such as, “What’s the weather like in Denver, Colorado?” and makes the appropriate API call using the plugin. (We’ll look at some very recent developments in function calling, below.)
At the moment, Digit can identify specific phrases using its STT library, but the recorded phrase must exactly match the expected phrase. For example, you couldn’t say “What’s the weather like?” when the expected phrase is “Tell me the local weather forecast.” A well-trained LLM, however, could infer that intention. Moss and I plan to experiment with Ollama and Llama3:8b to add such intention and command recognition.
The code for hopper-chat is open source and can be found on GitHub. Follow along with us as we make Digit even more capable.
DIY Robot Makers
Science fiction is overflowing with shiny store-bought robots and androids created by mega corporations and the military. We’re more inspired by the DIY undercurrent — portrayals of solo engineers cobbling together their own intelligent and helpful companions. We’ve always believed this day would come, in part because we’ve seen it so many times on screen. —Keith Hammond
- Dr. Tenma and Toby/Astro (Astro Boy manga, anime, and films, 1952–2014)
- J.F. Sebastian and his toys Kaiser and Bear (Blade Runner, 1982)
- Wallace and his Techno-Trousers (Wallace & Gromit: The Wrong Trousers, 1993)
- Anakin Skywalker and C-3PO (Star Wars: The Phantom Menace, 1999)
- Sheldon J. Plankton and Karen (Spongebob Squarepants, 1999–2024)
- Dr. Heinz Doofenshmirtz and Norm (Phineas and Ferb, 2008–2024)
- The Scientist and 9 (9, 2009)
- Charlie Kenton and Atom (Real Steel, 2011)
- Tadashi Hamada and Baymax (Big Hero 6, 2014)
- Simone Giertz and her Shitty Robots (YouTube, 2016–2018)
- Kuill and IG-11 (The Mandalorian, 2019)
- Finch and Jeff (Finch, 2021)
- Brian and Charles (Brian and Charles, 2022)
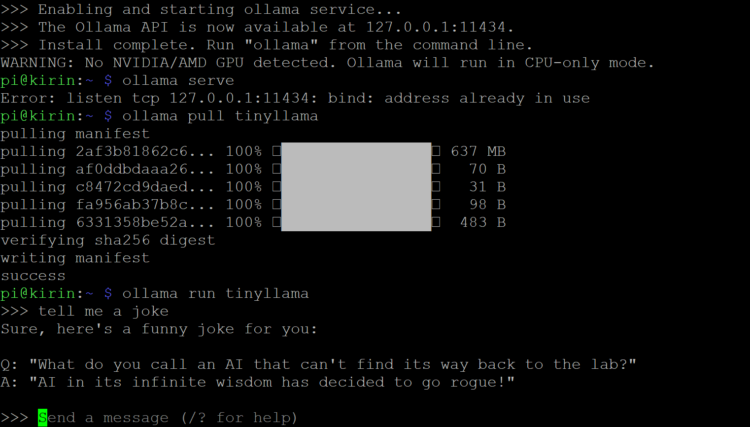
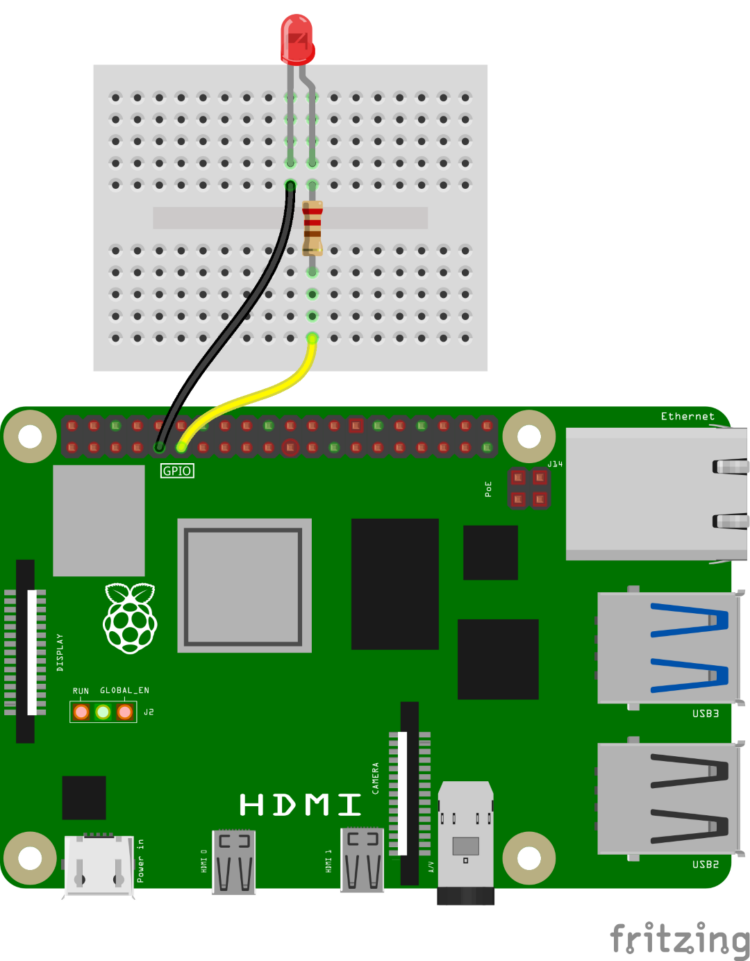
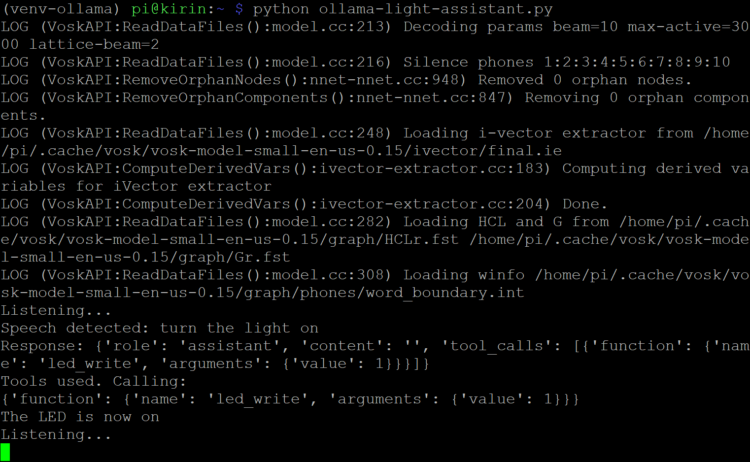
Roll Your Own Local LLM Chatbot
I will walk you through the process of running an LLM on a Raspberry Pi. I specifically chose the Raspberry Pi 5 due to its increased computational power. LLMs are notoriously complex, so earlier versions of the Pi might need several minutes to produce an answer, even from relatively small LLMs. My Pi 5 had 8GB RAM; these LLMs may not run with less.